Methodology
How the BizCrush STT benchmark works, end to end.
Why this benchmark
We publish this benchmark to give STT users a scoreboard for the apps they actually use — real-world audio, methodology fully visible — and to keep the numbers, audio, and transcripts here for anyone to review directly.
The conflict of interest is real (we build BizCrush and this benchmark); the rest of this page is what we do to bound it.
Test setup
The benchmark runs on real Android and iOS phones inside a custom acoustic isolation box. Each test plays reference audio through speakers inside the box; the phone under test records it as it would in any real environment. We moved from an Android emulator to real devices because the emulator's virtual mic path bypasses device-specific hardware AGC, mic tuning, and platform-level audio processing — none of which the emulator can replicate. Running on actual phones puts the entire user-facing audio chain in the loop, so scores reflect what the app really hears.
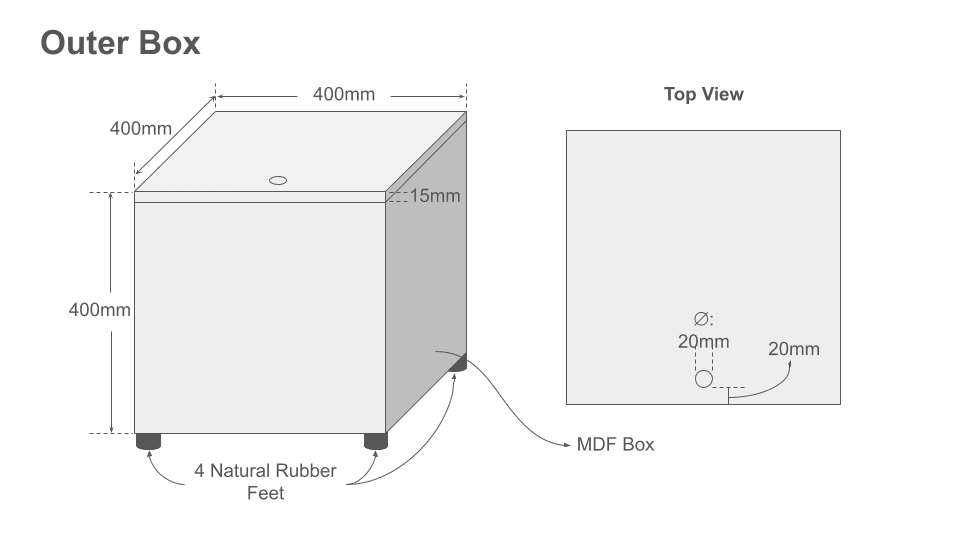
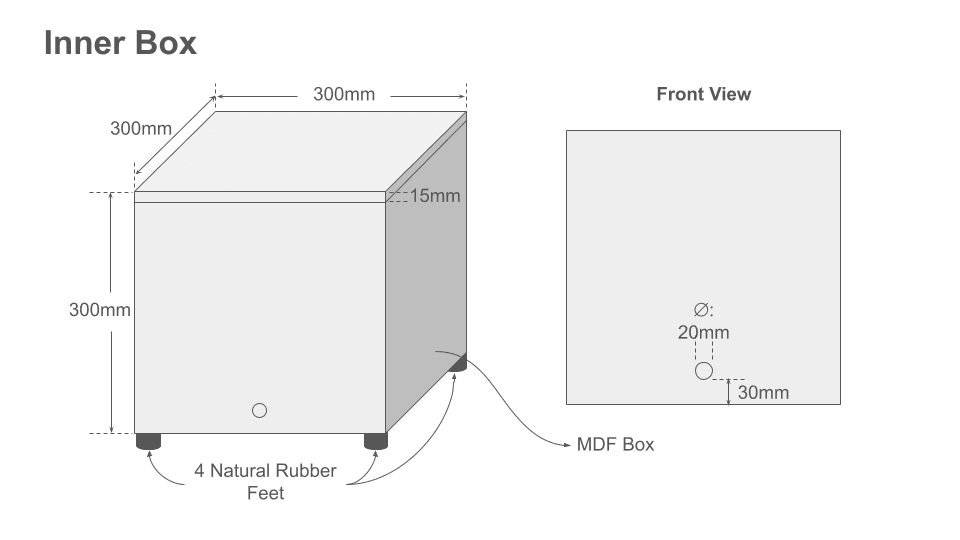
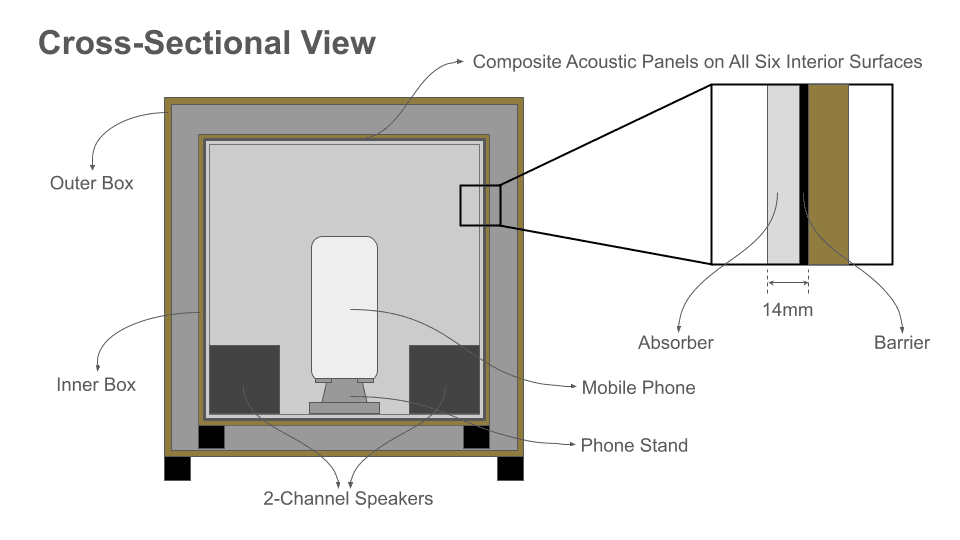
A dedicated Mac mini controls the entire test run — it plays the reference audio out to the two speakers inside the inner box and drives the phone under test through a data cable (USB-C / Thunderbolt-compatible). All cables enter through the hole on the outer box's lid and reach the inner box through the hole on its front panel. The two holes sit on different faces so any sound leaking out has to bend through a longer air path rather than travel in a straight line. The inner-box hole sits behind a composite acoustic panel; a small "+" cut in the panel in front of the hole lets the cables through. Both cable holes are then sealed with Blu-Tack around the cables to close the acoustic leak. The two speakers sit at the two corners of one wall inside the inner box; a phone stand on the opposite wall locks the phone at a fixed height and position facing the midpoint between the speakers, so every test presents the same acoustic geometry. Composite acoustic panels (absorber + barrier, 14mm total) line all six interior surfaces of the inner box, and the outer box adds a second isolation layer. Natural rubber feet on each box block vibration from the surface below so it doesn't reach the phone.
How a single test runs
- The harness opens the target app on the phone under test and taps record.
- It plays the reference audio clip through the two speakers inside the acoustic box; the phone's own microphone picks it up as it would in any real environment.
- While the recording is still running, it captures the engine's live transcript directly from the app — via the in-recording copy button on apps that expose one, or by polling the visible transcript view on apps that don't.
- After playback finishes, it waits a few seconds for any trailing recognition to flush, then captures the last bit of the Live transcript.
- It taps stop. What happens next depends on which transcript the test is capturing:
- Live test — the Live transcript was already captured in the steps above, so the recording session simply ends here.
- Post test — the app runs its AI post-processing after the stop tap, so the harness waits for it to finish and then captures the polished result.
- Each captured transcript is normalized and scored against the canonical reference, then enters the internal review queue. It isn't visible on the public site yet.
- A reviewer listens to the clip and compares the engine output against the audio. Reviewers cannot edit the engine output, the reference text, or the audio. For English WER runs, they can mark word-pairs as equivalent when the difference is orthographic but acoustically indistinguishable — e.g. "100 km" vs. "100 kilometers", numerals vs. spelled-out numbers, or other rendering differences the auto-normalizer can't catch generically (see the WER body in Scoring for canonical examples). Each mark drops the corresponding errors from the WER score. Any WER equivalence marks are shown on each published run alongside the transcripts, so any reader can see what was applied. Every mark's (reference, engine) word-pair is logged for later normalization-rule mining; reviewer identity is not stored. Korean runs are scored by CER and SER, neither of which supports reviewer marks: CER counts characters as-is, and SER's meaning-level judgments are the AI model's alone. For CER and SER the reviewer's job is a sanity check — read the numbers against the transcript and confirm nothing looks wildly off (a single judge run drifting far from the others, characters that clearly should have matched being counted as errors, etc.). SER especially is statistical, so a plausible-looking band is what "normal" means.
- Once the results look reasonable, the reviewer approves and the run becomes visible on this site.
Why we capture during recording
Most apps — ours included — run a post-stop pass over the whole transcript: punctuation, capitalization, occasional word fixes. The polish is helpful for end users but hides recognition errors. The displayed transcript ends up better than what the engine actually output.
Capturing live sidesteps that pass. The live capture still includes any inline AI cleanup the app layers on top as words arrive — that's a feature of the app's pipeline, not the engine itself, and we don't try to defeat it since it's what users actually see in the app.
We score the engine as users experience it in the app: inline cleanup included, post-stop polish excluded.
Live and Post transcripts
Many apps don't expose a Live transcript — they only reveal the polished transcript after you tap stop. We added a Post transcript capture (the post-stop, AI-rewritten result) so those apps can be benchmarked too.
Where an app exposes both, each is published as its own run, labeled Live or Post, so you can see exactly what the post-processing changed.
One caveat: some apps show identical text in the Live view and the Post view — either because they don't run post-processing, or because their "live" surface is actually the same field that gets rewritten in place after stop. In those cases the two runs will simply match. That's a property of the app, not a scoring artifact.
Disclosure
To keep every test verifiable, each published run shows the normalized reference and the normalized engine transcript side by side, so any reader can audit the score.
When an app exposes a way to export what the device actually recorded during the test, we upload that audio too and display it on the run page alongside the reference clip. It lets you hear what the phone's microphone picked up through the acoustic box — the same signal the engine had to work with.
We build a custom automation harness for each app we benchmark. However, the implementation details would identify the apps being tested, so we don't publish how each harness is built.
Scoring
Every transcript is normalized symmetrically on both sides (reference and engine output) before comparison so the metrics reflect acoustic accuracy rather than orthographic preference. Specifically:
- Casing & punctuation. Lowercased, parentheticals and stage directions like (laughter) stripped, timestamps stripped, punctuation removed (apostrophes preserved inside contractions), Unicode NFKC.
- HTML entities decoded. Source transcripts sometimes contain raw entities like &. We decode them before normalization, so 'R&D' in the source and 'R&D' from the engine become the same token.
- Thousand-grouping commas collapsed. 300,000 and 300000 are treated as the same token, since engines vary in whether they emit the comma.
- Spoken numbers canonicalized. Spelled-out cardinals and ordinals become digits on both sides: four → 4, ninety five → 95, twenty-first → 21st, hundred percent → 100 percent, '50s → 50s. Writing a spoken number as words or digits is a display choice, not a recognition error. Because the rewrite is symmetric, only identical spoken content converges — an engine that heard the wrong number still scores a substitution. Grammatical apostrophes (students', it's) are untouched and still count, like any other homophone spelling.
- Currency equivalence; percent canonicalized. If the reference says $3.3 billion and the engine emits 3.3 billion dollars, we count that as a match — the engine's form wins on both sides, so the diff renders them as identity rather than a substitution. Percent is simpler: % always expands to the word percent on both sides, so 0.6%, 0.6 percent, and hundred percent vs. 100% all meet at the same tokens.
- Speaker labels stripped. Diarization artifacts like Speaker 1 that engines sometimes emit aren't in the canonical reference, so they don't count as insertions.
With normalization applied, up to three metrics may be reported for a run. Each captures a different kind of accuracy; which ones the scoring pipeline computes for a given run depends on how that run was configured.
- WER Word Error Rate. Whitespace-separated tokens; counts substitutions, deletions, insertions. A reviewer can mark acoustically-equivalent pairs as equivalent — e.g. "100km" vs. "100 kilometers", or formatting variants the engine renders differently from the reference — so the score reflects acoustic accuracy rather than orthographic difference. Reviewer overrides of this kind apply only to WER.
- CER Character Error Rate. Character-level scoring; whitespace stripped from both sides before comparison. Useful where word boundaries are linguistically fuzzy or where edits are most informative one character at a time. CER does not support reviewer overrides — meaning-equivalent rendering differences (e.g. unit abbreviations like 100km vs. 100 kilometers) are handled by SER instead.
- SER Semantic Error Rate. An AI judge (LLM) identifies meaning-changing errors (substitutions, deletions, insertions). The AI judge is run over multiple independent passes (five by default), and we report the band across the successful passes (min / median / mean / max) plus the per-error word ranges, so every detected error can be inspected inline on the run detail page. Five successful passes is the minimum required for a complete SER. The AI judge's verdict is the published value — SER does not support reviewer overrides.
Limitations
- Today we test engines through their apps, which means scores reflect any inline AI cleanup the app layers on top of the engine. API-direct testing is on the roadmap and will be reported separately; in-app and API numbers for the same engine generally won't be directly comparable.
- Live-transcript capture is app-specific. Each engine exposes its in-progress transcript differently, so the harness has a per-app capture path. Adding a new engine requires manually mapping the right UI hooks.
- App version isn't auto-captured yet; comparisons across major engine releases are not (yet) explicit on this site.
- The corpus is small, and grows deliberately. License-free audio clips are hard to source, and well-written transcripts harder still — human reviewers create or refine each ground-truth transcript by listening to the audio directly, so the reference is accurate before any engine is scored against it.
Licenses & credits
Original BizCrush-generated audio and reference transcripts are © BizCrush — all rights reserved. They are published here so any reader can verify transcript accuracy by ear and against the displayed ground truth. Redistribution, derivative works, commercial use, and use as machine-learning training data are prohibited without prior written permission.
Third-party-sourced test audio and reference transcripts are reproduced from their original sources for the purpose of objective benchmarking. Copyright remains with the original creators; we credit each source on its clip page. The output transcripts produced by each engine are derivatives of the source audio and inherit its copyright posture.
Engine output transcripts are produced by the respective STT services and are reproduced here for accuracy comparison only. Trademark and product names belong to their respective owners.
For licensing inquiries about BizCrush-original content, or if you are a rights holder of any third-party clip in our corpus and would like attribution updated or content removed, contact us at help@bizcrush.ai.
Previous versions
Methodology changes are append-only: each prior version is preserved below so a score published under that version remains reproducible by reading the rules it was scored under.
Through 2026-07-15Android emulator-based test setup; before the acoustic isolation box was built.
Test setup — prior version
The benchmark ran on a dedicated Mac mini. Reference audio played through a virtual audio bridge (BlackHole + Multi-Output on macOS) into the Android emulator's mic input, where a real STT app picked it up. Using the speaker-to-mic path instead of calling the engine's API directly was intentional — what users experience in practice is the app's full audio pipeline, and the score should reflect that.
Multi-Output Device duplicated the audio to both the Mac's speakers and BlackHole, so playback could be monitored while BlackHole fed the emulator's mic. Without it, BlackHole would silently consume the playback.
The emulator setup was replaced on 2026-07-15 by a real-device rig inside a custom acoustic isolation box. See the current Test setup section for details, and the Updates page for the transition summary.
Through 2026-06-29Before SER (Semantic Error Rate) was added; all clips were scored by WER.
Scoring metrics — prior version
With normalization applied, the only metric actually used was WER. The corpus contained Latin-script and Korean clips only — no Japanese or Chinese — so CER was a documented option for CJK languages in principle but was never exercised.
WER — whitespace-separated tokens; counts substitutions, deletions, insertions. Raw Korean WER counted orthographic differences as errors even when they weren't audible — 띄어쓰기 (word-spacing) variations and spelling variants indistinguishable in fast speech (e.g. 있지마는 vs. 있지만은). A reviewer listened to each clip and marked such pairs as equivalent so the score reflected acoustic accuracy. WER also kept a distinction CER erases: 전 체조 선수 ("former gymnast") vs. 전체 조 선수 ("all-team player").
SER did not exist. Meaning-level scoring was implicit in the reviewer-marking step on WER, not surfaced as a separate metric.